Cassandra Data Modeling 心得筆記
2014-02-15
Tags: cassandra
使用 Cassandra 時要設計出合適的 Data Model 是件苦差事,這篇是基於 Cassandra 2.0 版本整理出的一些心得,有興趣的人可以參考一下。以下...正文開始!
目前找到比較好而且完整的文章是「Cassandra Data Modeling Best Practices」這份文章(
簡中版 part1,
簡中版 part2)(
原文版 part1,
原文版 part2),建議先把它整個讀過一遍。讀完後接著可以看看原作著以這份文章為基礎整理出來的下面這份投影片
不過,既然都用了 Cassandra 2.0,我想多數人應該會盡量用 CQL3 來操作資料,讓自己不要用的那麼痛苦。利用 CQL3 進行 Modeling 可以參考下面這份投影片
依據上面儿份資料,整理出的 Modeling 重點如下
- 中心思想
- 依據「系統如何查詢資料」來設計 Data Model
- 不要以傳統 RDBMS 的 relational table 思維來設計 Data Model,要把 column family 想成是 HashMap<RowKey, SortedMap<ColumnName, ColumnValue>>
- CQL 只是讓資料操作起來「長的像」RDBMS 的 relational table,Modeling 時請先忘掉 CQL
- 設計之初就要考量是不是會用到 Secondary Index
- 效能考量
- 使用 wide row,wide row 在 ordering, grouping, filtering 有效能優勢
- 使用合適的 row key (挑合適的 row key 其實就是在做 sharding) 以避免資料過度集中在 ring 上特定 node,因而避免發生 hotspot 危機
- 為了增加讀(select)寫(upsert)速度,Data Model 進行 De-normalize,部份 column family 許可發生 column duplicate。簡單來說就是用空間換取時間
- read-heavy data 跟 write-heavy data 放在不同 column family。如此一來 read-heavy data 可以常常進到 row cache,讀(select)資料時會快很多
- 熱門資料與冷門資料放在不同 column family
- 其它
- CQL3 的 compound primary key 摘要
- 語法範列
PRIMARY KEY(partition_key,clustering_column_1,clustering_column_2)
partition_key 對應到 column family 的 row key,clustering_column_1、clustering_column_2 則是 composite columnPRIMARY KEY((partition_key1,partition_key2),clustering_column_1,clustering_column_2,clustering_column_3)
partition_key1 + partition_key2 組合了 column family 的 row key,clustering_column_1、clustering_column_2、clustering_column_3 則是 composite column
- 圖解
- 先用 CQL3 執行下述指令產生 table 與資料
CREATE TABLE passbook (
user varchar,
date timestamp,
deposit int,
withdraw int,
PRIMARY KEY(user,date)
);
INSERT INTO passbook (user, date, deposit,withdraw) VALUES ('nekobean','2014-01-01',1000,10);
INSERT INTO passbook (user, date, withdraw) VALUES ('nekobean','2014-01-02',20);
INSERT INTO passbook (user, date, withdraw) VALUES ('nekobean','2014-01-03',30);
INSERT INTO passbook (user, date, withdraw) VALUES ('duke','2014-02-01',300);
INSERT INTO passbook (user, date, withdraw) VALUES ('duke','2014-02-02',200);
INSERT INTO passbook (user, date, deposit, withdraw) VALUES ('duke','2014-02-03',2000, 100); - 產生的資料利用 CQL3 與 CLI 查詢的對照如下圖
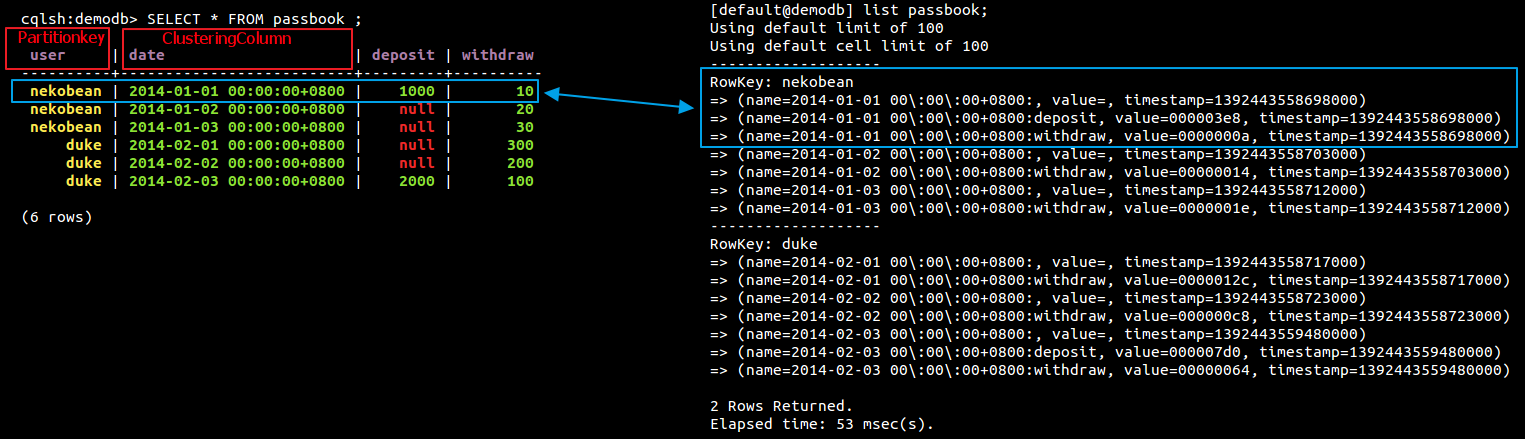
- 也可以參考 datastax 寫的這份文件裡針對 composite columns 章節設計出來的 timeline table 圖例解說
- 先用 CQL3 執行下述指令產生 table 與資料
- 語法範列
- CQL3 的 insert、update 語法在異動資料時都是做 upsert 動作。也就是說二者在異動資料的邏輯相同,資料不存在的話進行新增(insert)動作,資料若存在則進行更新(update)動作
- CQL3 的 compound primary key 摘要